
Bloated database harm query performance, unnecessary infra cost, and hinder development.
We can manage bloated tables by:
1. Drop Unused Tables
2. Archive Old Data
3. Table Partitioning
4. Index Maintenance
5. Vacuuming
Identify the Big Tables
We can use pg_total_relation_size() to calculate the total disk space used by the specified table, including all indexes and TOAST data.

SELECT
schemaname,
relname,
n_live_tup AS row_count,
(SELECT Count(1) FROM information_schema.columns WHERE table_schema = schemaname AND table_name = relname) AS col_count,
Pg_size_pretty(Pg_total_relation_size(relid)) AS total_size,
Pg_size_pretty(Pg_relation_size(relid)) AS rel_size,
Pg_size_pretty(Pg_indexes_size(relid)) AS idx_size
FROM pg_catalog.pg_stat_user_tables
ORDER BY Pg_total_relation_size(relid) DESCIf the row/tuple is too big, Postgres will compress and (maybe) move the data out of the main table. The process is called TOAST (The Oversized-Attribute Storage Technique). Queries involving large data objects stored in TOAST tables can be slower than those with smaller data objects.
-- list of TOAST tables and indexes
SELECT *
FROM pg_catalog.pg_class
WHERE relname LIKE 'pg_toast%';-- list of table that use TOAST
SELECT
schemaname,
relname,
toast_blks_read, -- Number of disk blocks read from this table's TOAST table (if any)
toast_blks_hit, -- Number of buffer hits in this table's TOAST table (if any)
tidx_blks_read, -- Number of disk blocks read from this table's TOAST table indexes (if any)
tidx_blks_hit -- Number of buffer hits in this table's TOAST table indexes (if any)
FROM pg_catalog.pg_statio_user_tables
WHERE toast_blks_read + toast_blks_hit + tidx_blks_read + tidx_blks_hit > 0;-- show storage/toast strategy
-- m = Main: This means no compression, no out of line storage. This is for data types which are not TOASTable at all.
-- p = Plain: Compression, but no out of line storage.
-- x = Extended: Compression and out of line storage.
-- e = External: No compression, but out of line storage.
SELECT psut.schemaname, psut.relname, pa.attname, atttypid :: regtype, attstorage
FROM pg_catalog.pg_statio_user_tables psut
join pg_catalog.pg_attribute pa ON psut.relid = pa.attrelid
WHERE psut.toast_blks_read > 0;1. Drop Unused Tables
Sometimes we need to create a temporary table during data migration or handle the issue which is usually safe to be dropped later on. We can check whether there is a name convention for temporary tables (like tmp_* , temp_* , *_backup , etc) within the organization.
SELECT table_catalog, table_schema, table_name, table_type
FROM information_schema.tables
WHERE
table_schema NOT IN ( 'pg_catalog', 'information_schema' )
AND ( table_name LIKE 'tmp_%' OR table_name LIKE 'temp_%' OR table_name LIKE '%_backup' ); Table statistics like pg_catalog.pg_status_user_table give useful information about the overall table activity:
-- find least read tables
SELECT schemaname, relname, seq_tup_read, idx_tup_fetch
FROM pg_catalog.pg_stat_user_tables
ORDER BY seq_tup_read + idx_tup_fetch ASC;
-- find least write tables
SELECT schemaname, relname, n_tup_ins, n_tup_del, n_tup_upd
FROM pg_catalog.pg_stat_user_tables
ORDER BY n_tup_ins + n_tup_del + n_tup_upd ASC;
-- find empty tables
SELECT schemaname, relname,n_live_tup
FROM pg_catalog.pg_stat_user_tables
WHERE n_live_tup < 1; Check when the last data is inserted into the table at audit columns (if you don’t have audit columns, you should start to implement it)
Always consult with product engineers and make a backup before dropping the table
2. Archive Old Data
Old data that is not relevant anymore to show/process by the application can be archived (move to separate and cheaper storage) and after a while to be deleted/pruned. Archiving can benefit overall performance, storage cost, data security, and regulation compliance.
3. Table Partitioning
Splitting what is logically one large table into smaller physical pieces.

Horizontal Partition
PostgreSQL offers built-in support for partitioning by range, by list, and by hash. Each partitioned tables have the same number of columns, but fewer rows.
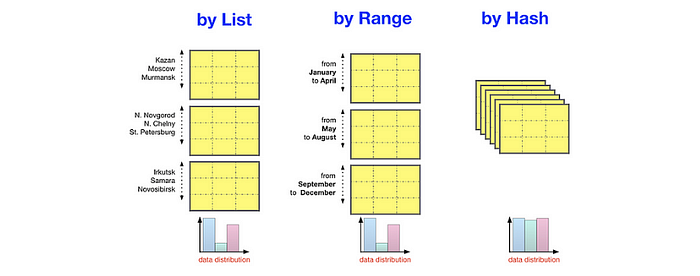
No need to remember all partition names, the operation (SELECT/UPDATE/INSERT/DELETE) is still using the parent/master table. Make sure you put the right criteria for SELECT to trigger the partition.
-- Declarative partitioning by list
CREATE TABLE customers (id INTEGER, status TEXT, arr NUMERIC) PARTITION BY LIST(status);
CREATE TABLE cust_active PARTITION OF customers FOR VALUES IN ('ACTIVE');
CREATE TABLE cust_archived PARTITION OF customers FOR VALUES IN ('EXPIRED');
CREATE TABLE cust_others PARTITION OF customers DEFAULT;
-- Declarative partitioning by range
CREATE TABLE partners (id INTEGER, status TEXT, arr NUMERIC) PARTITION BY RANGE(arr);
CREATE TABLE partners_arr_small PARTITION OF partners FOR VALUES FROM (MINVALUE) TO (25);
CREATE TABLE partners_arr_medium PARTITION OF partners FOR VALUES FROM (25) TO (75);
CREATE TABLE partners_arr_large PARTITION OF partners FOR VALUES FROM (75) TO (MAXVALUE);
-- Declarative partitioning by hash
CREATE TABLE sellers (id INTEGER, status TEXT, arr NUMERIC) PARTITION BY HASH(id);
CREATE TABLE sellers_part1 PARTITION OF sellers FOR VALUES WITH (modulus 3, remainder 0);
CREATE TABLE sellers_part2 PARTITION OF sellers FOR VALUES WITH (modulus 3, remainder 1);
CREATE TABLE sellers_part3 PARTITION OF v FOR VALUES WITH (modulus 3, remainder 2);-- query from partitioned tables
SELECT * FROM customers WHERE status = 'ACTIVE';
SELECT * FROM cust_active;
-- Although id#1 have status 'ACTIVE' but it will lookup to all partitioned table before return the result
EXPLAIN SELECT * FROM customers WHERE id = 1; Partitioning existing tables may be a delicate process and please note the limitation e.g. range partition does not allow NULL values.
Vertical Partitioning
On Vertical Partitioning, we move some columns to new tables. The (partitioned) tables will have different columns but the same number of rows. No special feature/tool to achieve this, it is simply a table redesign process.
The implementation is quite straightforward, use INSERT INTO SELECT to copy the data and ALTER TABLE to remove columns.
The tricky part is to decide which column needs to be moved. We must refer to existing queries and make sure the new table doesn’t complicate the query (avoid the JOIN statement).
4. Index Maintenance
Indexing can help improve query performance but it is not without cost. It uses up space and slows down data modification. Index maintenance activities include analysis of index uses, routine reindexing, and removal of unused indexes.
-- duplicate index
SELECT pg_size_pretty(sum(pg_relation_size(idx))::bigint) as size,
(array_agg(idx))[1] as idx1, (array_agg(idx))[2] as idx2,
(array_agg(idx))[3] as idx3, (array_agg(idx))[4] as idx4
FROM (
SELECT indexrelid::regclass as idx, (indrelid::text ||E'\n'|| indclass::text ||E'\n'|| indkey::text ||E'\n'||
coalesce(indexprs::text,'')||E'\n' || coalesce(indpred::text,'')) as key
FROM pg_index) sub
GROUP BY key HAVING count(*)>1
ORDER BY sum(pg_relation_size(idx)) DESC;
-- unused index
SELECT s.schemaname,
s.relname AS tablename,
s.indexrelname AS indexname,
pg_relation_size(s.indexrelid) AS index_size
FROM pg_catalog.pg_stat_user_indexes s
JOIN pg_catalog.pg_index i ON s.indexrelid = i.indexrelid
WHERE s.idx_scan = 0 -- has never been scanned
AND 0 <>ALL (i.indkey) -- no index column is an expression
AND NOT i.indisunique -- is not a UNIQUE index
AND NOT EXISTS -- does not enforce a constraint
(SELECT 1 FROM pg_catalog.pg_constraint c
WHERE c.conindid = s.indexrelid)
AND NOT EXISTS -- is not an index partition
(SELECT 1 FROM pg_catalog.pg_inherits AS inh
WHERE inh.inhrelid = s.indexrelid)
ORDER BY pg_relation_size(s.indexrelid) DESC;5. Vacuuming
PostgreSQL implements concurrency control through MVCC (Multi-Version Concurrency Control) which caused data records not directly updated/deleted after the statement execution. A dead tuple refers to a row or record in a table that has been marked for deletion/update but has not yet been physically removed from the table.
Postgres have a vacuuming process (VACUUM commands) to reclaim dead tuples space. It automatically triggers periodically by AUTOVACUUM the daemon.
There are two variants of VACUUM: standard VACUUM and VACUUM FULL. VACUUM FULL can reclaim more disk space but runs much more slowly. Standard VACUUM can run in parallel with other database operations (SELECT/UPDATE/INSERT/etc).
VACUUM FULL has performance implications because it will lock the entire table. It is not recommended to run VACUUM FULL unless there is a very high percentage of bloat, and queries are suffering badly. We should consider the least activity database time to perform it.
Tune-up the AUTOVACUUM is a better approach in the longer term to make sure no bloated dead tuples.
Epilogue
The author wishes to give at least some hints to start but many details are still open to discussion. Share your experiences and wisdom on managing a bloated database.
